
|
Home | Libraries | People | FAQ | More |
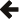


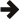
You might be curious as to the performance of this naive key-value blob database. I was, so I performed the following benchmarks on Win8.1 NTFS and Linux ext4 both on SSD using the code above. Note that the test uses OpenMP to parallelise the operations, so the below shows AFIO in a worst case light as will be explained shortly:
I don't know about you, but I was more than quite surprised at how good the performance is considering its naive simplicity. As a reference comparison, with durability disabled these NoSQL key-value databases achieve the following performance (source):
Table 1.5. Performance for various NoSQL databases with fsync disabled on Linux ext4:
|
Our naive design |
Cassandra |
Couchbase |
HBase |
MongoDB |
|
|---|---|---|---|---|---|
|
Insertion |
25,576 |
53,067 |
40,063 |
38,991 |
18,038 |
|
Lookup |
64,495 |
38,235 |
14,503 |
3,955 |
2,752 |
The naive results were calculated by excluding the highest value and averaging the next three highest values. Now this is not a fair comparison by any means — the NoSQL databases are running over a network stack (which particularly penalises read performance) whereas ours is direct to the OS API more or less, and our naive benchmark only writes 10 bytes of value per item which is small enough to pack into the inode on both NTFS and ext4, so the extent allocator is never getting invoked. Still, one is used to thinking of the filesystem as incredibly slow and to be avoided with fancy database software — this simple test shows that recent filesystems are competitive to fancy databases (and indeed even more so with a more sophisticated design than the one we used, as you will see later).
![[Note]](../../../../../../doc/src/images/note.png) |
Note |
|---|---|
NTFS has such poor insertion performance because Microsoft Windows
performs a sequentially consistent flush of the containing directory
on file handle close, whereas Linux doesn't even flush the containing
directory after you fsync a file and you must explicitly fsync the
directory itself. You may find the |
As is fairly obvious from the results, AFIO lags far behind iostreams
at about one half to one third the performance. We are using AFIO's synchronous
API for the most part, and that is simply a get() on the asynchronous API which introduces
an unnecessary thread sleep (the fully asynchronous edition is about
0-5% faster). Much more importantly, because no platform provides asynchronous
file open nor close, AFIO emulates asynchronicity by executing the file
opens and closes in a threadpool which is exactly what the iostreams
does via OpenMP, however there isn't a copy of ASIO and AFIO and all
the futures and completion handlers standing in between, so the iostreams
implementation is far faster and will always
be faster than AFIO if you do a lot of file opens and closes which is
pretty much this benchmark in a nutshell.
|
Note |
|---|---|
This peer review edition of AFIO v1.40 uses a mocked up v1.40 API based on the v1.3 series engine. Performance of this mockup will be considerably below the final v1.40 engine written using Boost.Outcome's lightweight futures. |
A design which makes better use of AFIO is one which is asynchronous throughout and which avoids file opens and closes (tip: always avoid file opens period if you want fast filesystem performance, they are always very slow due to the security checking of every single item in the path. File closes are also particularly slow on Microsoft Windows and Apple OS X).
Some might think that the flat store of all the keys in a single directory
would scale poorly to item count. This certainly used
to be true for the previous generation of filing system, however modern
filing systems usually have between O(log N)
to O(1) lookup
complexity and between O(N) and O(1)
insertion complexity — this author found excellent lookup performance
with 10M items on ext4 and NTFS, though insertion performance was not
great for NTFS (which does a directory flush each file close).
Problem 1 with naive design: We are doing too many file opens and closes for really good performance.
Problem 2 with naive design: Atomicity: Writes do not atomically appear fully completed to other readers, so if one thread/process reads a value currently being written by another thread/process, they will see a partially written value which is a filesystem race.
Problem 3 with naive design: Consistency: If a writer process fatal exits during a write and therefore does not complete a write, the key value store is corrupted.
Problem 4 with naive design: Isolation: There is no concurrency ordering control apart from that provided by the operating system. AFIO exposes the strong guarantees made by operating systems as to the atomicity of read and write visibility to other readers and writers (see each API reference documentation page for the guarantees per API per platform), however the STL iostreams wrapper around AFIO ruins those guarantees (this is why AFIO does not provide iostreams wrappers).
Problem 5 with naive design: Durability: If power loss occurs during use of the key-value store, you are at the mercy of random chance as to what data in what order reached physical storage. On many filing systems you aren't even guaranteed that extent metadata matches contents, so your value may consist of portions of valid data intermixed with garbage.
Problem 6 with naive design: Insertion
and update complexity may be as poor as O(N) on some filesystems.
Problem 7 with naive design: There is no way of atomically updating two or more key-value items in a transaction.
Luckily, AFIO exposes exactly the right features to make five of those seven problems go away with very few changes to the above code.