
|
Home | Libraries | People | FAQ | More |
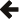


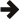
Let's see how this second generation ACI(D) design benchmarks compared to the first AFIO implementation where the dotted lines are the previous generation design:
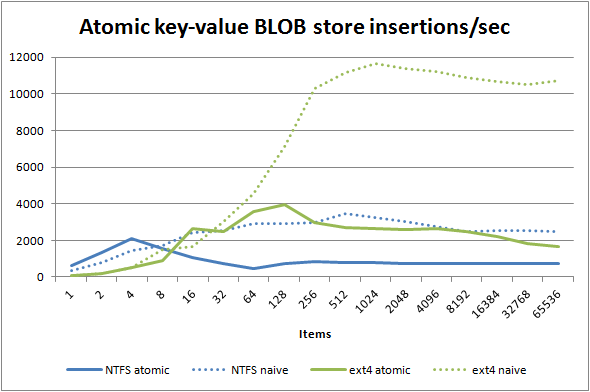
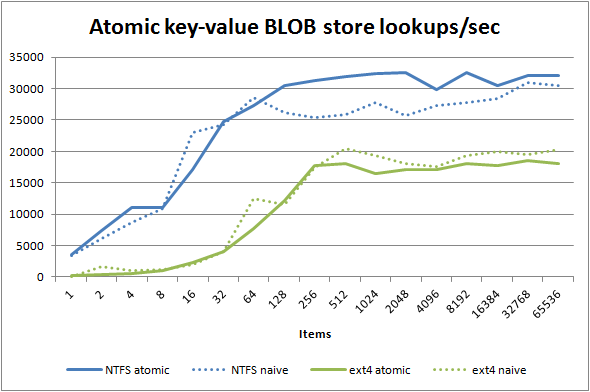
Lookups are actually not better — we are comparing the synchronous naive design to an asynchronous design, so the asynchronous design pulls ahead a bit on Microsoft Windows. Note, though, that the extra directory indirection costs you a noticeable amount of performance on ext4 — perhaps as much as 15% once you include the 10% bump from the asynchronous API.
Insertions are however diametrically slower: about four times slower on both NTFS and ext4. This is because atomic renames appear to not parallelise well — both filing systems are gating hard at about four parallel atomic renames (the number of cores on my test CPU), and if you throttle the parallelism by hand you'll find performance is really only half that of the first generation design which is logical as we are committing twice the new items to before. This is a good example of where Intel's Hyperthreading can really penalise overall performance sometimes: filing systems tend to parallelise linearly to real CPU core count only.
This second generation design is actually quite solid, and assuming that the design rationale is correct about the sequential consistency of journalling file systems then this key-value store design is likely production code useful, especially if you are storing large blobs which you might like to individually memory map. What you don't have though is the ability to update key-values as a transaction, and insertion performance is already heading downwards towards less than 1000 items/second which bodes poorly for adding transaction support.
Out of curiosity, how might we add transaction support to this design? One's first thought is a lock file of some sort, perhaps even a lock file for the entire store. AFIO v1.3 can push about 3000 exclusive lock files per second (see the mini-programs on atomicity following this section) so you might imagine holding a global lock file during reads and during a sequence of multiple atomic renames which make up committing a transaction.
Unfortunately, while that strategy would work well most of the time,
it falls down spectacularly in the situation of power loss. The problem
you have is that you have no way at all of forcing the order of key-value
updates to reach physical storage. You might think that calling fsync()
or using O_SYNC and then
writing each item sequentially might work, but imagine if power is lost
in the middle of that sequence: how do you know if the store you are
now looking at was in the middle of a transaction, and if so what needs
to be rolled back?
If you think this through, you realise that you need some form of write log from which an interrupted sequence of operations can be reconstituted and either completed or discarded to return a store to a consistent state. This write log is called a journal by journalling file systems, and is called various things by databases (write ahead logging, rollback journal etc). It has the special property that it is always moving forwards in time and what it records is the sequentially consistent history of the database.
You have probably guessed what the final part of this workshop tutorial does: and indeed it is implementing a transactional write log.